
Cómo entender las fórmulas prescriptivas de los audífonos sin morir en el intento


La adaptación audioprotésica ha evolucionado mucho más allá de la simple amplificación del sonido. Hoy trabajamos con modelos prescriptivos complejos, sistemas de normalización de sonoridad, algoritmos específicos por fabricante y nuevos enfoques híbridos que buscan un ajuste más preciso en función del usuario real. Sin embargo, para aplicar correctamente estas herramientas es necesario comprender de dónde venimos, qué fundamentos sostienen cada fórmula y qué limitaciones persisten en la práctica clínica.
Qué es realmente una fórmula de adaptación
Una fórmula prescriptiva es el conjunto de características de amplificación necesarias para compensar una pérdida auditiva concreta. Su propósito es transformar un audiograma en una prescripción, considerando factores como la intensidad del input, el rango dinámico disponible y la percepción de la sonoridad.
Breve historia: del espejo del audiograma a la media ganancia
Las primeras aproximaciones intentaban igualar la pérdida: si el paciente tenía 50 dB de pérdida en 1 kHz, se aplicaban 50 dB de ganancia.
Pronto se comprobó que esto producía niveles poco confortables. La práctica clínica llevó a la Half-Gain Rule:
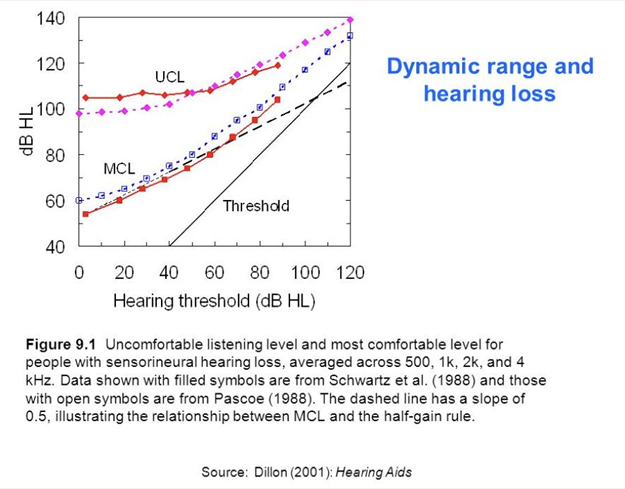
- Ganancia ≈ 0,5 × umbral
- Para 50 dB HL → 25 dB de ganancia
Este principio sigue siendo la base implícita de varias fórmulas modernas, aunque hoy se modula en función de la frecuencia y del rango dinámico disponible.
Limitaciones y desafíos en el diseño de fórmulas
Existen varios problemas clave a los que se enfrenta cualquier sistema prescriptivo:
- La ganancia óptima depende del nivel de entrada.
- No es sencillo medir la percepción real de sonoridad.
- La aclimatación modifica preferencias con el tiempo.
- Existen preferencias individuales entre confort vs inteligibilidad.
- La presencia de dead regions (regiones muertas cocleares) compromete la utilidad de la amplificación en determinadas zonas.
Revisión de las fórmulas clásicas y sus principios
POGO y POGO II
Basadas en la regla de media ganancia, incorporan un recorte en bajas frecuencias para reducir enmascaramiento.
En POGO II se compensan pérdidas severas (>65 dB).
NAL-R y NAL-RP
Su objetivo es maximizar la inteligibilidad percibida sin provocar una sonoridad global excesiva. Se busca que todas las bandas de habla tengan una sonoridad equivalente.
Se integran:
- El LTASS
- Las curvas de igual sonoridad
- La pendiente de la pérdida auditiva
Se aplican correcciones específicas por frecuencia y grado de pérdida.
DSL (Desired Sensation Level)
La fórmula DSL, especialmente en pediatría, persigue garantizar audibilidad completa del habla en todas las bandas sin priorizar la igualación de sonoridad.
Es una prescripción orientada al desarrollo del lenguaje y propone niveles más elevados de amplificación en comparación con NAL.
La era de la compresión: normalizar la sonoridad
La transición hacia sistemas no lineales se fundamenta en la necesidad de comprimir el rango dinámico reducido del usuario.
Diferencia clave
En la imagen que te muestro muestra lo siguiente:
- Las fórmulas lineales mantienen la ganancia fija.
- Las fórmulas con compresión adaptan la ganancia al nivel de entrada, reduciendo la distorsión perceptiva y evitando molestias.
LGOB, IHAFF, ScalAdapt
Estos modelos requerían mediciones subjetivas de sonoridad y ajustaban la ganancia para normalizarla.
FIG6
Prescribe tres niveles de ganancia para inputs de 40, 65 y 95 dB SPL según el umbral del paciente.
No distingue por frecuencia, lo que limitó su adopción clínica.
DSL v5.0 y NAL-NL2: los estándares actuales
DSL v5.0
Amplía la lógica DSL y añade ajustes según edad, tipo de pérdida, binauralidad y niveles de confort.
Incluye correcciones para:
- Conductivas (eleva UCL un 25% del ABG).
- Binaurales (resta 3 dB).
- Adultos (reduce ganancia frente a niños).
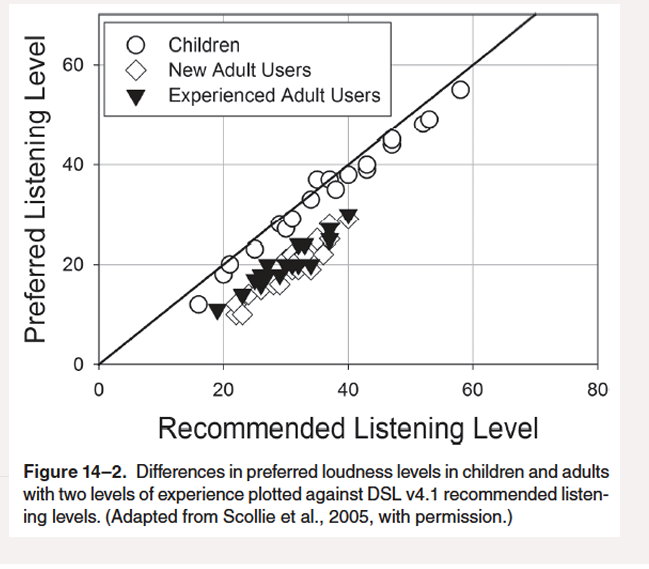
La figura que te muestro muestra diferencias en la preferencia de niveles entre niños, nuevos usuarios y usuarios experimentados.
NAL-NL2
Su objetivo sigue siendo maximizar inteligibilidad, no restaurar la sonoridad normal.
Introduce variables demográficas y lingüísticas:
- Sexo
- Edad
- Experiencia con audífonos
- Lengua tonal vs. no tonal
- Binauralidad
- Componente conductivo
La siguiente tabla compara directamente NAL-NL2 con DSL v5.0, destacando diferencias clave en ganancia, manejo de ruido y tratamientos de la vía conductiva.
| Categoría | NAL-NL2 | DSL v5.0 |
|---|---|---|
| Experiencia del usuario | Incorpora más ganancia para usuarios experimentados, en función del grado de pérdida auditiva. | No aplica correcciones según experiencia. |
| Género | Aumenta 1 dB para hombres y reduce 1 dB para mujeres. | No realiza ajustes por género. |
| Adaptación bilateral | Reduce los objetivos en 2 dB para entradas bajas y 6 dB para entradas altas. | Reduce los objetivos en 3 dB en todos los niveles de entrada. |
| Escucha en ruido | No realiza correcciones específicas. | Reduce 3–5 dB en las frecuencias de menor importancia para el programa de ruido. |
| Componentes conductivos | Prescribe ganancia para la componente neurosensorial y añade el 75% de la brecha aéreo-ósea. | Aumenta el UCL previsto en un 25% de la brecha aéreo-ósea, lo que resulta en un incremento menor de ganancia total. |
| LDLs | No se tienen en cuenta. | Acepta LDLs específicos del paciente. |
NAL-NL3: hacia un modelo modular
NL3 abandona la idea de una única curva de prescripción y la sustituye por un sistema modular ajustable a perfiles y escenarios concretos (pérdidas mínimas, confort en ruido, etc.).
Su despliegue completo se prevé a lo largo de 2026.
Fórmulas de fabricante: variaciones sobre NAL
Aquí las diferencias clave entre fabricantes. Cada uno ajusta compresión, ganancia y enfoque vocal de forma única:
ReSound (Audiogram+): evita ganancia excesiva en altas para audiometrías descendentes; diferencias en relación de compresión respecto a NAL-NL2.
Oticon (VAC+): compresión alineada a la voz para favorecer inteligibilidad; menos compresión en frecuencias medias y altas.
Phonak (ADP 2.0): compresión adaptativa; ganancia lineal para señales de entrada alta.
Signia (IX Fit): doble compresión con dos kneepoints; enfoque más orientado al confort (menos ganancia en medias y más en altas).
Starkey (e-STAT 2.0): menor ganancia que NAL-NL2 en entradas medias y altas; ajuste más conservador según el audiograma.
Verificación: los 5 dB que pueden cambiar una adaptación
La importancia de medir con REM (Real Ear Measures): Hablaremos en otros articulos sobre como aplicar correctamente el REM.
- El objetivo es quedar dentro de ±5 dB del target.
- Inconsistencias entre frecuencias afectan la autogestión del volumen por parte del usuario.
La verificación obliga a abandonar la adaptación “a ojo” y convierte la prescripción en un proceso basado en evidencias.
Suscríbete con tu email para no perderte nada 👇



